
안녕하세요 😉
유유자적한 개발자 유로띠 입니다 😀

👏👏👏👏
이번 포스팅에서는
✅ 랭체인 데이터 연결
✅ 체인
에 대해서 알아보겠습니다
랭체인 데이터 연결과 체인에 대해서
데이터 연결(data connection)은 일반적인 데이터 분석 환경에서 ETL(Extract, Transform, Load)에 해당하며,
데이터를 한 곳에서 다른 곳으로 옮기는 과정을 말합니다.
추출 - 변환 - 적재의 과정을 거칩니다
랭체인의 데이터 연결도 이와 동일하게 다음 구성요소에 따라 진행합니다.
문서 가져오기(Load) - 문서 변환(Transform) - 문서 임베딩(Embed) - 벡터 저장소(Store) - 검색기(Retrieve)
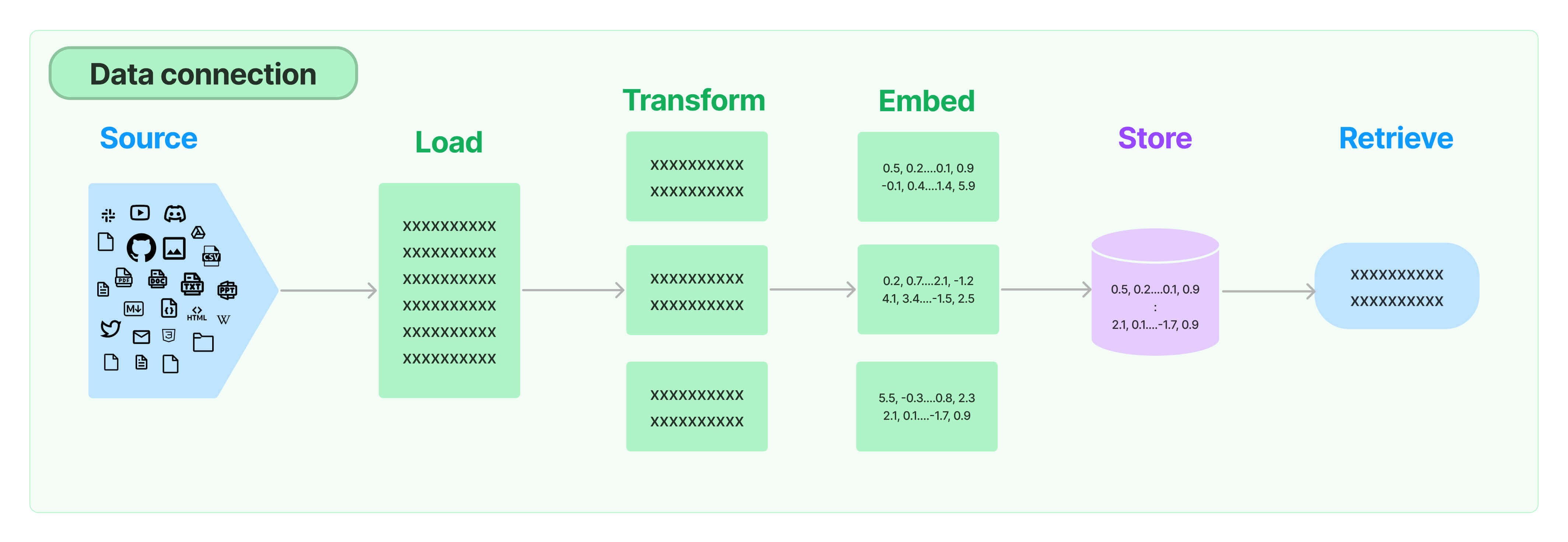
✅ 랭체인 데이터 연결
라이브러리 설치
필요한 라이브러리를 설치합니다
!pip install langchain==0.1.13
!pip install openai==1.14.2
!pip install pypdf==3.17.4
!pip install tiktoken==0.5.2
!pip install faiss-cpu==1.8.0
!pip install sentence-transformers==2.2.2
!pip install langchain-openai
!pip install python-dotenv==1.0.1
pypdf: 파이썬에서 PDF 파일을 다루기 위한 라이브러리입니다.
tiktoken: 오픈AI에서 제공하는 임베딩을 위한 라이브러리입니다. OpenAIEmbeddings을 사용하기 위해 필요합니다.
faiss-cpu: 페이스북(Facebook)의 AI 연구팀이 개발한 라이브러리로, 벡터의 유사도 검색을 위해 사용됩니다.
sentence-transformers: 자연어 처리에서 문장 또는 단락을 벡터로 변환하기 위해 사용되는 라이브러리입니다.
문서 가져오기 (: pdf 업로드)
로컬에 있는 pdf를 불러옵니다.
책에서는 톰 소여의 모험(The_Adventures_of_Tom_sawyer)이란 파일을 사용하였습니다.
로컬의 적당한 위치에 파일을 넣고 불러옵니다.
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/The_Adventures_of_Tom_Sawyer.pdf")
document = loader.load()
document[5].page_content[:5000]
document[5].page_content[:5000] : 페이지 인덱스는 0부터 시작하기 때문에 6페이지 중 5000글자를 읽어오라는 의미입니다.

임베딩
데이터를 가져온 후 임베딩 처리를 진행합니다. 임베딩은 데이터를 벡터로 변환하는 작업입니다.
from langchain_community.vectorstores.faiss import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
db = FAISS.from_documents(document, embeddings) # 임베딩 처리
임베딩 모델을 openai 또는 HuggingFace를 사용하면 벡터는 다르게 표현될 수 있어도 검색 시 사용하는 모델과는 무관합니다.
즉, HuggingFace로 임베딩 후 openai로 검색해도 상관없는 거죠
검색
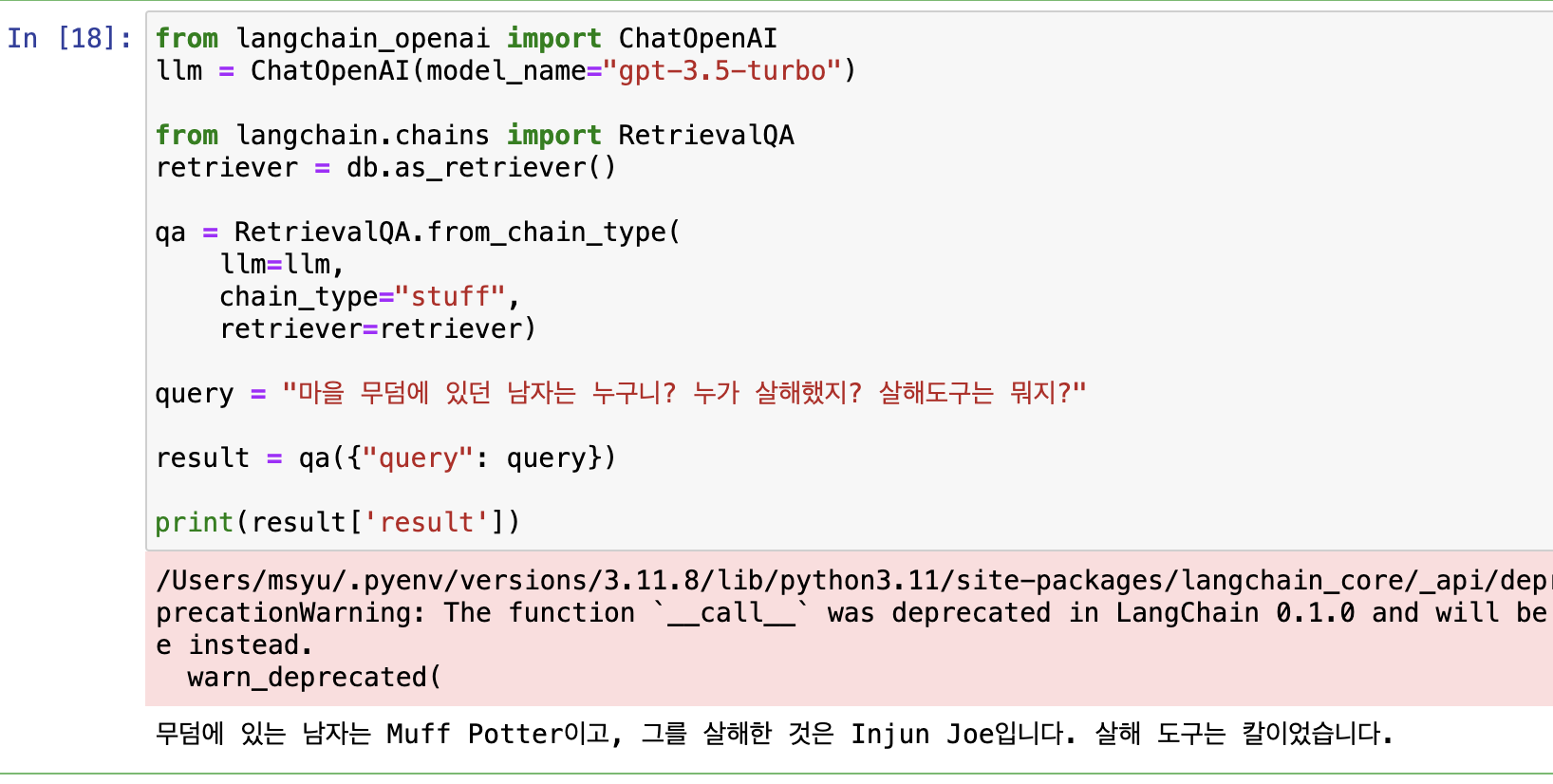
RetrievalQA 검색기를 활용하여 질문에 답변을 할 수 있도록 합니다.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
from langchain.chains import RetrievalQA
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever)
query = "마을 무덤에 있던 남자는 누구니? 누가 살해했지? 살해도구는 뭐지?"
result = qa({"query": query})
print(result['result'])
✅ 체인
체인(chain)은 여러 구성 요소를 조합해서 하나의 파이프라인을 구성해 주는 역할을 합니다.
라이브러리 설치
!pip install langchain==0.1.13
!pip install openai==1.14.2
!pip install langchain_openai
체인은 일반적으로 LLMChain을 사용합니다.
다음은 영어 문장(sentence)을 한글로 번역(translation) 한 후 다시 요약(summary)하도록 합니다.
# 프롬프트1 정의
prompt1 = PromptTemplate(
input_variables=['sentence'],
template="다음 문장을 번역하세요: \n\n{sentence}"
)
# 번역(체인1)에 대한 모델
chain1 = LLMChain(llm=llm, prompt=prompt1, output_key='translation')
# 프롬프트2 정의
prompt2 = PromptTemplate.from_template("다음 문장을 한 문장으로 요약하세요. \n\n{translation}")
# 요약(체인2)에 대한 모델
chain2 = LLMChain(llm=llm, prompt=prompt2, output_key="summary")
from langchain.chains import SequentialChain
all_chain = SequentialChain(
chains=[chain1, chain2],
input_variables=['sentence'],
output_variables=['translation', 'summary'],
)
# 번역하고 요약해야 할 영어 문장
sentence = """
One limitation of LLMs is their lack of contextual information (e.g., access to some specific documents or emails).
You can combat this by giving LLMs access to the specific external data.
For this, you first need to load the external data with a document loader.
LangChain provides a variety of loaders for different types of documents ranging from PDFs and emails to websties and YouTube videos.
"""
all_chain_result = all_chain.invoke(sentence)
print(all_chain_result)
{'sentence': '\nOne limitation of LLMs is their lack of contextual information (e.g., access to some specific documents or emails).
\nYou can combat this by giving LLMs access to the specific external data.
\nFor this, you first need to load the external data with a document loader.
\nLangChain provides a variety of loaders for different types of documents ranging from PDFs and emails to websties and YouTube videos.
\n',
'translation': '\nLLMs의 한계 중 하나는 문맥 정보의 부족입니다 (예: 특정 문서나 이메일에 대한 액세스).
이를 극복하기 위해 LLMs에게 특정 외부 데이터에 대한 액세스를 제공할 수 있습니다.
이를 위해 먼저 문서 로더를 사용하여 외부 데이터를 불러와야 합니다.
LangChain은 PDF와 이메일부터 웹사이트와 유튜브 비디오까지 다양한 유형의 문서에 대한 로더를 제공합니다.',
'summary': '\n\nLLMs의 문맥 정보 부족은 외부 데이터 액세스로 해결할 수 있으며,
LangChain은 다양한 유형의 문서를 로드하는 로더를 제공합니다.'}
'Programming > AI' 카테고리의 다른 글
| [LLM] 랭체인 part 1, 프롬프트 모듈 사용해보기 (feat: 환경 셋팅) (0) | 2024.03.30 |
|---|---|
| 로컬에서 가성비있게 chatGPT 사용하기 (feat: ollama-webui) (4) | 2024.02.03 |
| ollama로 로컬에서 나만의 AI 챗봇 만들기 (45) | 2024.02.01 |