MongoDB에서 nGram 사용하기(fts, search index)
안녕하세요 😉
유유자적한 개발자 유로띠 입니다 😀

👏👏👏👏
이번 포스팅에서는
✅ n-gram 이란?
✅ search Index 설정하기
에 대해서 알아보겠습니다
n-gram 이란?
✅ 전문 검색의 종류
n-gram을 설명하기 앞서 먼저 전문 검색하는 종류에 대해서 간단히 살펴볼게요
전문 검색의 아키텍처는 종류가 많이 있는데, 그중에 가장 많이 사용하는 3가지를 소개할게요
📍 grep 형
grep형은 검색 대상 문서를 처음부터 전부 읽어가는 가장 단순한 아키텍처입니다.
단순하게 구현한다면, big-O로 계산하면 O(텍스트의 길이 x 검색 대상의 검색어의 길이) 만큼 상당한 시간이 걸립니다.
장점은 즉시성이 좋고, 검색누락이없으며, 병렬화하기가 매우 간단하다는 특징이 있습니다.
📍 Suffix 형
Suffix형은 검색 가능한 형태로 검색 대상 전문을 보유하고 있습니다.
전부 메모리에 올릴 수 있는 형태이기 때문에 빠르게 검색할 수 있습니다.
이론적으로는 가능하지만, 정보량이 크므로 실제 아키텍처를 가진 엔진은 구현하기 어려운 단점이 있습니다.
📍 역 인덱스(Inverted Index) 형
역 인덱스형은 단어와 문서를 연관짓는 것입니다.
검색하기 전에 인덱스를 전처리로 만들어야 하는 특징이 있습니다. 그렇기 때문에 즉시성이 뛰어나지 않고
구현 방법에 따라서는 검색누락이 생길 수 있지만, 인덱스를 압축함으로써 대규모화하기가 쉽습니다.
뒤에 소개할 n-gram은 역 인덱스 방식의 알고리즘입니다.
그렇다면 역 인덱스는 어떤 구조로 되어 있을까요? 🤔
✅ 역 인덱스의 구조
역 인덱스의 구조는 크게 Dictionary, Postiongs 두 파트로 나뉩니다.
🔵 term = 문서 내의 단어, 문서를 검색할 수 있는 단위
🔵 Dictionary = term(단어)의 집합
🔵 Postiongs = term(단어)을 포함하고 있는 문서는 몇 번인지 나타내는 배열
예를 들어 볼까요? 😏

데이터라는 단어로 검색을 했다라는 행위는 Dictionary(데이터, 사이언스, 실무, 경쟁력)에서 데이터를 찾아서 이에 연결되어 있는 Postiongs를 얻습니다. 그러면 Postiongs내에는 1, 2, 3번 문서가 있음을 알 수 있습니다.
즉, 역 인덱스는 term을 포함하는 문서를 즉시 발견할 수 있는 구조로 되어 있습니다.
그러면 Dictionary는 어떻게 만드는 걸까요? 🤔
Dictionary를 만들 때에는 언어의 단어를 term으로 다루는 방법, 문자를 적당한 단위로 나누는 방법이 있습니다.
언어의 단어를 term으로 다루는 방법:
🔸사전을 사용하는 방법
🔸형태소 분석 방법
단어가 아닌 문자를 적당한 단위로 나누는 방법:
🔸n-gram 기법
정리하면, 전문 검색 시 역 인덱스 방식을 사용하고 n-gram이란 기법을 이용하여 역 인덱스를 만들어서 사용한다. 라고 볼 수 있습니다.
그래서 n-gram은 뭔가요? 🤔
✅ n-gram 이란?
n-gram은 텍스트를 n자씩 잘라낸 것입니다.
3 문자씩 잘라내면 3-gram, tri-gram이라 부르고, 2 문자씩 잘라내면 2-gram, bi-gram이라고 합니다.
예를들어, '사이언스'를 2-gram으로 한 경우 다음과 같이 분할됩니다.
'사이' '이언' '언스'

양쪽에 포함된 문서번호를 구하는 처리는 교집합(intersection)으로 처리하여, 1, 2, 4번 문서가 검색됩니다.
교집합이면 1, 2번만이 아닌가? 생각할 수도 있을 텐데요. 검색어인 term을 기준으로 교집합을 구한다라고 볼 수 있습니다.

Search Index 생성하기
이제 n-gram에 대해서 알아보았고
MongoDB Atlas를 기준으로 n-gram으로 검색이 가능한 Search Index를 생성해 보겠습니다.

✅ create Search Index
MongoDB atlas에서 Search 탭에 create index를 선택합니다.

Visual Editor를 이용하여 Search Index를 생성해 보도록 하겠습니다.

생성할 index 이름과 Database, Collection를 선택해서 next를 진행합니다.
저는 강의(courses) 정보가 있는 Collection에 search index를 생성하려고 합니다.

기본적인 정보가 나올 텐데요, 여기서 하단의 Refine Your Index를 선택하여 n-gram 설정을 해야 합니다.

표준(standard) 대신 한글 형태소 분석기인 nori를 선택합니다. index Analyzer, Search Analzer는 동일하게 설정하는 것이 좋습니다.

여기까지만 진행하면 기본적인 검색을 위한 index 생성입니다.
여기서 더 나아가서 검색 방식을 n-gram으로 하기 위한 설정입니다.
하단의 Field Mappings를 선택합니다.

검색 대상이 되는 컬럼(Field)를 선택하고 n-gram 사용을 위해 Data Type을 Autocomplete로 선택합니다.
마찬가지로 Analyzer를 nori로 설정하고 문자를 최소, 최대 몇 단위로 잘라서 할지 설정합니다.
nGram도 여러 종류(edgeGram, rigthEdgeGram, nGram)가 있는데, 기본적인 nGram으로 선택합니다.
Flod Diacritics는 분음 부호(발음 구별 기호)에 대해서 무시할지 여부인데, 기본 설정대로 true로 선택하여 진행합니다.

최종적으로 저장을 진행하고 생성을 완료합니다.
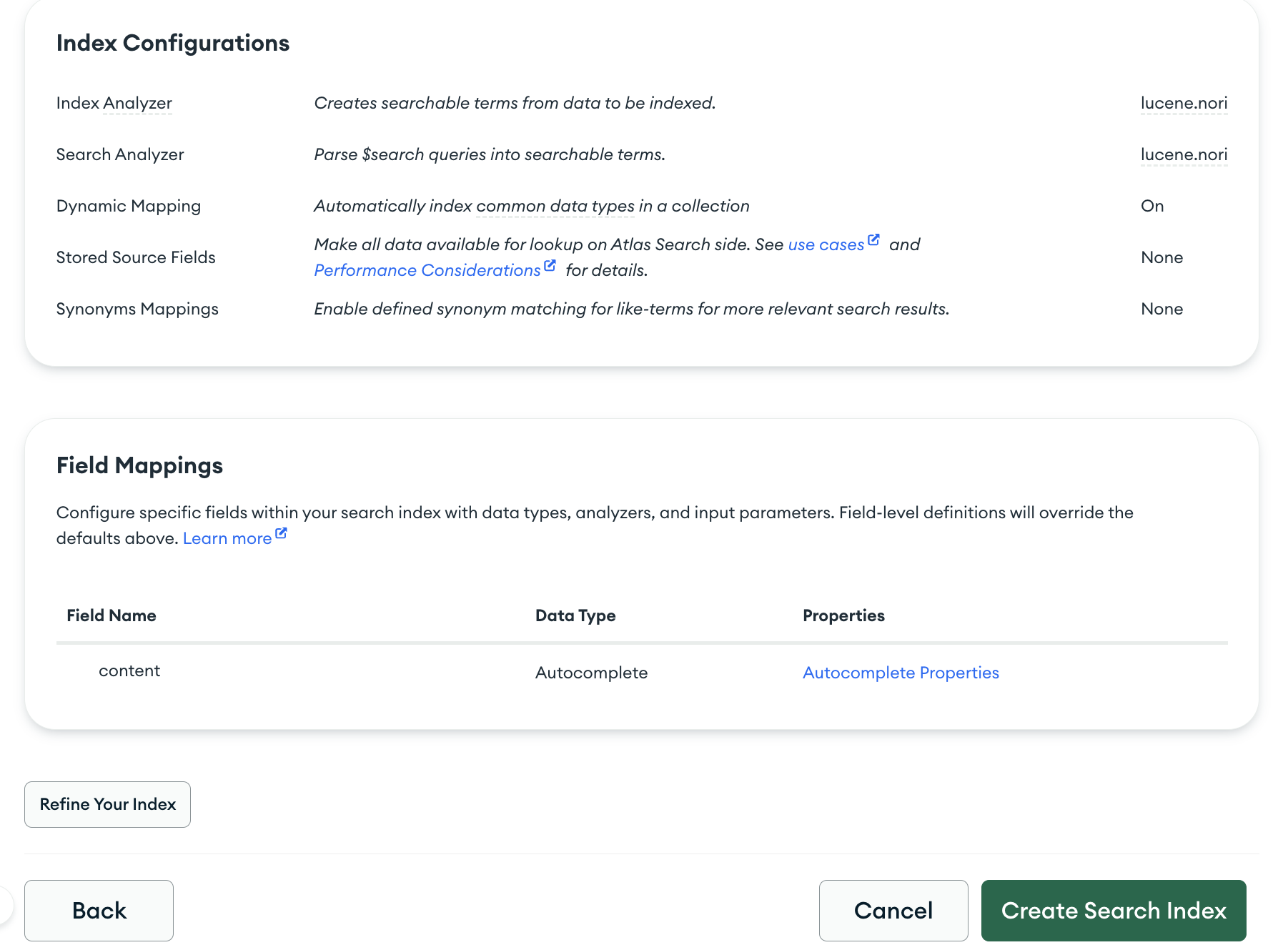
정상적으로 생성된 것을 확인할 수 있습니다. 😄
Collections 데이터가 있다면 동기화까지 시간이 다소 소요됩니다. (NOT STARTED -> INITIAL SYNC -> ACTIVE)



MongoDB Atlas의 장점 중 하나는 UI에서 Search Tester가 가능합니다.
✅ 검색 테스트
생성된 인덱스를 선택하고 왼쪽 탭의 Search Tester를 선택합니다.
그리고 오른쪽에 Edit $Search Query를 선택합니다.

기본적으로 다음과 같이 설정되어 있습니다.

우리가 생성한 index를 이용하여 검색을 시도해 보겠습니다.
매핑 정보를 생성할 때, Data Type을 autocomplete로 생성하였기 때문에 text -> autocomplete로 변경합니다.
저 같은 경우는 검색 대상(Field)을 content로 생성하였기 때문에 path에 content를 입력하였습니다.
그리고 검색 쿼리는 query에 입력하여 검색을 진행하시면 됩니다.


⭐️ 참고
대규모 서비스를 지탱하는 기술 - 전문 검색기술 도전
대규모 서비스를 지탱하는 기술 - YES24
이 책은 대규모 서비스를 개발, 운용하는 기술자를 위한 입문서다. 하테나가 학생을 대상으로 개최하는 인턴십에서 수행하는 실제 기술 강의를 기반으로 구성되어 있다. 계속해서 성장하고 있
www.yes24.com
MongoDB Atlas
MongoDB Atlas | 멀티 클라우드 개발자 플랫폼
MongoDB Atlas는 유일한 멀티 클라우드 개발자 데이터 플랫폼으로, 데이터를 사용해 빠르고 손쉽게 구축할 수 있습니다. 지금 무료로 시작하세요!
www.mongodb.com